

The inspection tool finishes scanning a 300 mm wafer. Thousands of high-resolution images pile up in the buffer. The inline system is waiting on one answer: defect or good, which bin, stop the lot or let it run?
The engineer standing at the tool does not care about benchmark scores or leaderboard performance. The real question is much simpler: can this model make the right decision, fast enough, on the computer inside the tool? The inline system may need an answer in under 20ms, while maintaining 98%+ classification accuracy and 0% escape rates.
That is where most "state-of-the-art" models quietly fall apart.
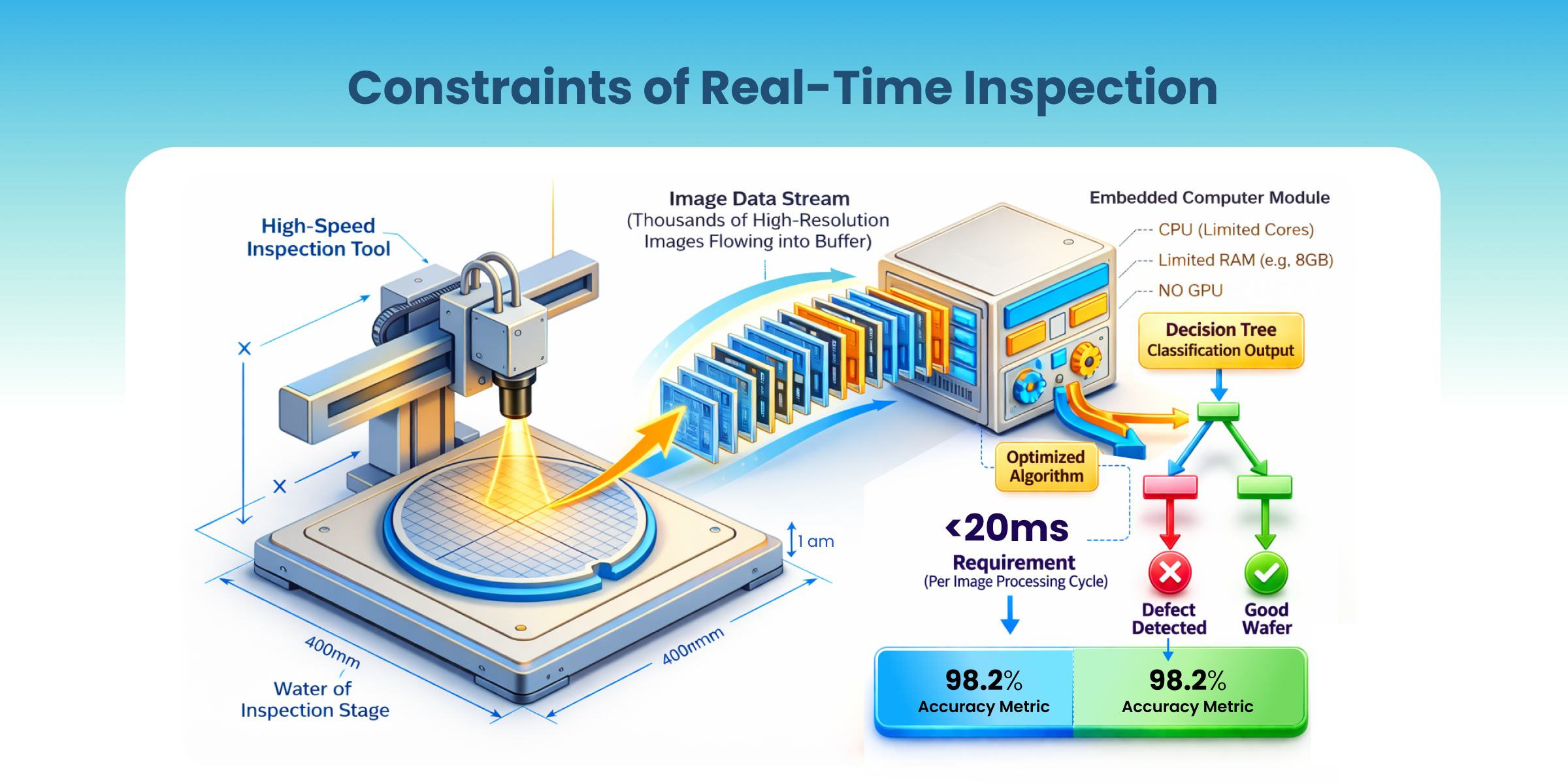
Figure 1: Wafer Inspection Production Constraint
The real problem is deployment, not accuracy
In semiconductor manufacturing, especially for auto defect classification (ADC) and auto wafer classification (AWC), good lab performance is only the starting point.Getting it to run reliably inside the machine, at production speed, on constrained hardware, is the actual engineering challenge.
Those are two different problems.
A model can look excellent offline and still fail on the fab floor. The gap usually comes from three places: throughput constraints, production reliability, and adaptation to the real fab environment.
Why strong lab models still fail in production
1. Throughput and hardware constraints are real
Cycle time is money. An extra 100 ms per image, multiplied across 200,000 images an hour, translates directly to OEE loss and real dollars.
The hardware inside the tool is not a server rack. It is limited with constrained Memory, power, and thermal headroom. Models that run comfortably in a cloud environment simply won't boot or run too slow inside production equipment.
The data volumes are brutal. A single inspection station can push 10,000 to 500,000 images per day. Running full-resolution heavy inference on all of it is not a performance concern, it is too expensive to be practical.
2. Production reliability matters more than small offline gains
On a benchmark, a small increase in accuracy can look meaningful. In production, that is not always the metric that matters most.
Stability beats marginal accuracy every time. On a benchmark, a small increase in accuracy can look meaningful. In production, that is not always the metric that matters most. A model that is slightly more accurate but introduces latency spikes, unstable behavior, or inconsistent outputs becomes hard to trust. Engineers will choose a system that is predictable, stable, and fast over one that is marginally better on an offline test but harder to operate in a live environment.
Production AI has to behave like production software. It has to be dependable every day, not impressive once.
3. Real fabs are messy, specific, and hard to generalize across
Every fab is different. Tools are different. Layers are different. Recipes are different. Defect signatures are different. A generic model trained on some other process fails quickly. Small-data adaptation to the actual production context is what matters.
Rare defects have almost no labels. The killer defects that actually hurt yield appear infrequently and are barely represented in any training set. Injecting prior knowledge from a foundation model and then compressing it toward the edge is currently the most practical path for handling this.
At scale, every watt and every gigabyte shows up in the tool quote. Deploying across 200+ tools means hardware costs compound fast. Model footprint directly affects capex, deployment cost, and it's not just a technical consideration anymore.
Why current SOTA still misses the mark
Many top-performing models in papers and benchmarks were never built for this environment. They are often too large for embedded hardware, too slow for machine-speed inference, trained on natural images rather than tool-specific signatures, and hungry for labeled samples that fabs cannot easily generate. In semiconductor production, the real objective is broader: accuracy, speed, stability, and deployability all at once.
The best benchmark score in the world does not survive first contact with a fab floor if it cannot meet the deployment constraints.
The architecture that actually works in production
The architecture that holds up in practice is usually not one large model. It is a staged system.
First, pretrain a large foundation model on substantial semiconductor data, including both labeled and unlabeled examples. This step is expensive, but it builds domain-specific priors that generic vision models do not have.
Next, distil the large model into a smaller intermediate model. The goal is to retain the useful semiconductor knowledge while reducing compute cost and model size.
Then fine-tune the intermediate model for the actual production target: a set of tools, layers, or defects.
After that, distil it again into a compact model sized to fit inside the equipment.
Then at inference, apply a dynamic routing: drop uninformative pixels early, route easy images through a low-resolution path, and escalate full compute only for the hard cases, typically 5 to 8% of images. The other 92% get a fast, lightweight decision.
This stack is how you get both accuracy and machine-speed at the same time. It is not a compromise between them.
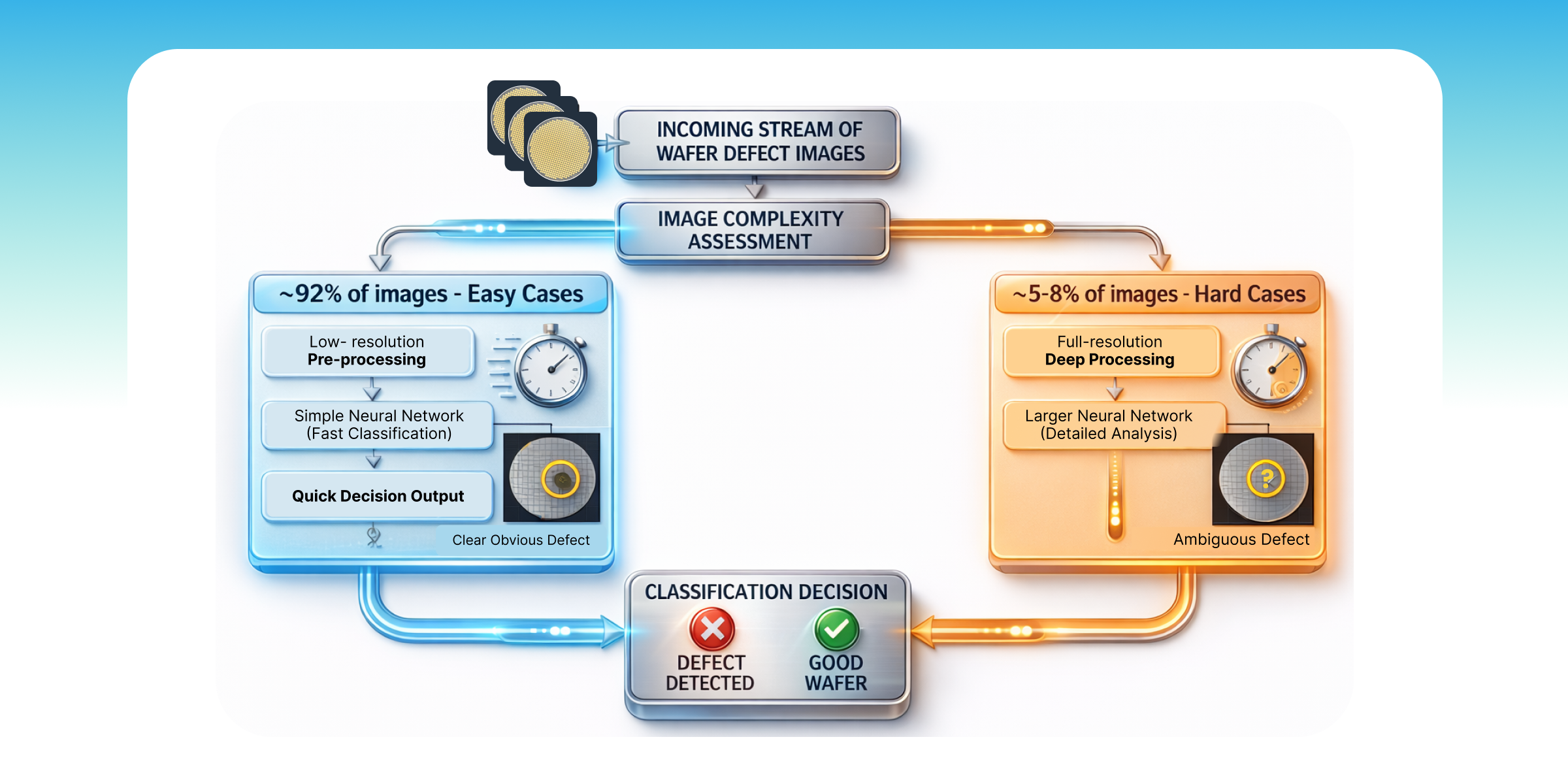
Figure 2: Dynamic Routing Inference System
Closing thought
The fab does not need AI that is only smart. It needs AI that is operationally deployable, trained on the right domain, adapted to the right context, compressed to the right size, and efficient enough to keep pace with the machine.
The future of manufacturing AI is not one monolithic cloud model. It is a hierarchy where the large model learns, the intermediate model adapts, and the fast model decides on the tool, at production speed, wafer after wafer.
The best model is not the one with the highest parameter count. It is the one that makes the right call in the right place without slowing anything down.
Curious whether others are running into the same wall, strong research performance that does not survive the move to production. What is the hardest deployment constraint you have hit?